基于模糊云认知诊断模型的学生分数预测方法及装置
1.本发明涉及教育数据挖掘技术领域,尤其涉及一种基于模糊云认知诊断模型的学生分数预测方法及装置。
背景技术:
2.目前已存在一些认知诊断模型(cognitive diagnosis model,cdm)和学生分数预测方法(predicting examinee performance,pep)。
3.(一)认知诊断模型
4.认知诊断模型可以大致分为离散型和连续型两类,这两种类型的认知诊断模型中最具代表性的分别是题目反应理论(item response theory,irt)和dina模型(deterministic inputs,noisyand
‑
gate model)。
5.irt假设每个学生都有一种独特的潜在特质,结合学生在具有区分度、难度等特征的试题上的做题情况,将学生建模为一维的连续能力值,用其代表学生的综合能力值。irt的双参数反应模型具体表示为:
[0006][0007]
公式(1)中,p(x
ij
=1|θ)为具有潜在特质θ的学生i正确回答试题j的概率;a和b分别为试题的区分度和难度;d是经验常数。然而,irt存在许多明显的局限性,例如难以满足一维假设,计算复杂等。
[0008]
dina模型不仅将学生在试题上的作答情况作为输入,同时结合试题与考察知识点的关联矩阵q,将学生建模成一个在多维知识点上的掌握向量。在已知学生i的知识点掌握向量α
i
={α
i1
,α
i2
,
…
,α
ik
}的情况下,可根据公式(2)计算学生i对试题j的掌握程度。
[0009][0010]
公式(2)中,q
jk
为试题j是否考察了知识点k;η
ij
为学生i是否可以正确回答试题j,η
ij
=0表示学生i无法正确回答试题j,η
ij
=1表示学生i可以正确回答试题j。然而,传统的dina模型只针对客观题进行诊断,即答案只有对和错两种结果,未考虑学生在主观题上的答题情况;此外,dina模型在使用em算法(maximum expectation algorithm,最大期望算法)时,其时间复杂度为指数级。
[0011]
针对传统的dina模型无法有效诊断主观题的问题,有人提出了一种面向学生个性化学习的模糊认知诊断框架(fuzzycognitive diagnosis framework,fuzzycdf),fuzzycdf将学生的认知能力表示为模糊集合的隶属度,并采用模糊交和模糊并对客观题和主观题的认知作答进行建模。然而,fuzzycdf仅用一个整数或模数实数来描述学生对知识点的掌握程度,忽略了学生认知状态的不确定性和波动性,导致认知诊断结果存在误差。此外,由于fuzzycdf采用mcmc(markov chainmonte carlo,马尔科夫链蒙特卡洛算法)进行参数估计,并引入额外的参数,进一步增大了计算负担。
[0012]
针对传统的认知诊断模型采用设计的公式评估学生认知状态,有人将深度学习应用到认知诊断,提出了neuralcdm。neuralcdm利用神经网络对学生、试题以及学生与试题直接的交互过程进行建模,增强了模型的学习能力,提升了认知诊断的准确性。然而神经网络普遍存在解释性差,以及训练神经网络的计算负担过大等问题。
[0013]
综上,将现有的认知诊断模型,例如dina模型、fuzzycdf和neuralcdm等,应用于大规模数据的认知诊断时,均存在明显的局限性。
[0014]
(二)学生分数预测
[0015]
学生分数预测通常采用矩阵分解的学生分数预测和基于认知诊断模型的学生分数预测。
[0016]
1)矩阵分解的学生分数预测
[0017]
矩阵分解(matrix factorization,mf)被广泛应用在推荐系统中,也被用于预测学生得分的研究。它通过构造学生和试题的低维矩阵,刻画学生和试题在低维空间中的表现程度,并据此实现预测学生得分。典型的研究思路包括:利用奇异值分解对学生进行建模;利用矩阵分解对考试成绩进行预测,并将预测结果与回归方法进行比较,对比结果表明矩阵分解有效的提高了预测的精度;将已成功应用于推荐系统的多关系因子分解方法,用于智能辅导系统的学生建模,并预测学生未来的考试成绩。
[0018]
然而,传统的矩阵分解存在解释性较差的问题,例如,通过矩阵分解模型得到学生的潜在因子和试题的潜在因子,再利用两种因子进行得分预测,由于潜在因子不能直接指明学生和试题的具体特征,因此得到的预测结果难以解释。
[0019]
2)基于现有的认知诊断模型的学生分数预测
[0020]
认知诊断模型以学生在试题上的作答情况作为输入,对学生进行个性化的认知建模,从而得到学生的潜在知识水平的掌握情况。
[0021]
dina模型引入试题失误率和试题猜测率对学生真实的答题情况进行建模,具有认知状态α
i
的学生i答对试题j的概率p
j
(α
i
)的计算公式为:
[0022][0023]
公式(3)中,s
j
为试题j的失误率,即学生掌握了试题j考察的所有知识点但是仍然答错的概率;g
j
为题目j的猜测率,即学生没有掌握试题j考察的所有知识点但是答对的概率;η
ij
为学生i对试题j的掌握程度;r
ij
为学生i在试题j上的实际得分。
[0024]
fuzzycdf提出预测学生试题得分的计算公式为:
[0025]
p(r
ij
=1|η
ij
,s
j
,g
j
)=(1
‑
s
j
)η
ij
+g
j
(1
‑
η
ij
)
ꢀꢀꢀꢀ
(4)
[0026]
公式(4)中,p()为学生答对试题的概率;(1
‑
s
j
)η
ij
为学生i掌握了试题j考察的所有知识点并正确解答的概率;g
j
(1
‑
η
ij
)表示学生i未掌握试题j考察的所有知识点但仍然正确解答的概率。
[0027]
然而,由于现有的认知诊断模型存在上述局限性,因此基于现有的认知诊断模型的分数预测方法在海量数据的在线学习场景下仍然存在分数预测准确度不足和计算效率低的问题。
技术实现要素:
[0028]
基于此,有必要针对背景技术中的上述技术问题,提供一种基于模糊云认知诊断
模型的学生分数预测方法及装置。
[0029]
基于上述目的,本发明实施例提供一种基于模糊云认知诊断模型的学生分数预测方法,包括:
[0030]
建立学生认知云模型;
[0031]
根据所述学生认知云模型的求解结果,获取学生在知识点上的掌握程度区间数;
[0032]
根据所述知识点掌握程度区间数,获取所述学生对试题的掌握程度区间数;
[0033]
根据迭代训练获得的目标模型参数和所述学生对试题的掌握程度区间数,获取试题的预测得分。
[0034]
优选地,所述建立学生认知云模型,包括:
[0035]
设定学生分值论域和学生认知论域,并根据所述学生分值论域中的得分对于所述学生认知论域的隶属度定义学生认知云;
[0036]
获取数字特征集,所述数字特征集中包含认知期望、认知熵和认知超熵;
[0037]
根据所述数字特征集建立学生认知云模型。
[0038]
优选地,所述根据所述学生认知云模型的求解结果,获取学生在知识点上的掌握程度区间数,包括:
[0039]
获取考察了知识点k的试题集对应的试题数量,并检测所述试题集对应的试题数量是否大于预设道数;
[0040]
若大于预设道数,则通过逆向认知云算法对学生i在知识点k上的学生认知云模型c
cik
进行求解,获得认知期望认知熵和认知超熵的特征值,并将所有所述特征值输入组合评价模型,获得所述学生i在知识点k上的掌握程度下限和掌握程度上限其中,所述逆向认知云算法为:
[0041][0042]
上式中,和分别为所述学生i在知识点k上认知期望、认知熵和认知超熵;为得分集合r
′
ik
的集合大小,得分集合r
′
ik
为所述学生i在考察了知识点k的试题集上的得分集合,可以表示r
′
ik
={r
′
ik1
,r
′
ik2
,
…
},r
′
ikm
为所述学生i在考察了知识点k的第m道试题上的得分;
[0043]
所述组合评价模型为:
[0044][0045]
上式中,w为所述学生认知云中认知超熵的权重;
[0046]
根据所述学生i在知识点k上的掌握程度下限和掌握程度上限获取所述学生i在知识点k上的掌握程度区间数
[0047]
优选地,所述根据所述学生认知云模型的求解结果,获取学生在知识点上的掌握程度区间数,还包括:
[0048]
若小于预设道数,则认为确定学生认知云模型无效,并通过概率矩阵分解方法预测学生得分。
[0049]
优选地,所述根据所述知识点掌握程度区间数,获取所述学生对试题的掌握程度区间数,包括:
[0050]
检测试题j所属的试题类型;
[0051]
在试题j属于客观题时,获取与所述客观题匹配的第一模糊评价模型,并根据所述第一模糊评价模型获取所述学生i对客观题的掌握程度下限和掌握程度上限其中,所述第一模糊评价模型为:
[0052][0053]
上式中,和分别为所述学生i在知识点k上的掌握程度下限和掌握程度上限;q
jk
为试题j是否考察了知识点k;∩为模糊交;
[0054]
在试题j属于主观题时,获取与所述主观题匹配的第二模糊评价模型,并根据所述第二模糊评价模型获取所述学生i对主观题的掌握程度下限和掌握程度上限其中,所述第二模糊评价模型为:
[0055][0056]
上式中,∪为模糊并;
[0057]
根据所述学生i对主观题和客观题的掌握程度下限和掌握程度上限获取学生i对主观题和客观题的掌握程度区间数
[0058]
优选地,所述目标模型参数包含试题失误率和试题猜测率,所述根据迭代训练获得的目标模型参数和所述学生对试题的掌握程度区间数,获取试题的预测得分,包括:
[0059]
对于主观题和客观题,将试题失误率s
j
、试题猜测率g
j
和所述学生i对试题j的掌握程度区间数输入得分预测模型,以获得试题j的得分预测区间数其中,所述得分预测模型为;
[0060]
[0061]
上式中,和分别为所述学生i在试题j上的预测得分上限和预测得分下限;
[0062]
根据所述得分预测区间数计算所述学生i在试题j上的预测得分f
ij
;其中,所述预测得分f
ij
的计算公式为:
[0063][0064]
s.t.|r
′
ik
|>n
[0065]
上式中,|r
′
ik
|为考察了知识点k的试题集对应的试题数量;n为预设道题。
[0066]
优选地,所述基于模糊云认知诊断模型的学生分数预测方法,还包括:
[0067]
获取模糊云认知诊断模型的参数先验分布和联合后验分布,并根据所述参数先验分布和所述联合后验分布对模型参数进行初始化;
[0068]
在模型迭代过程中,从预设参数区间采样获得待定的各模型参数,并计算各模型参数的转移概率;
[0069]
基于所述待定的各模型参数和所述转移概率训练所述模糊云认知诊断模型,并在迭代次数达到预设迭代阈值时,获得目标模型参数。
[0070]
此外,本发明实施例还提供一种基于模糊云认知诊断的学生分数预测装置,包括:
[0071]
认知云建模模块,用于建立学生认知云模型;
[0072]
知识点掌握程度表征模块,用于根据所述学生认知云模型的求解结果,获取学生在知识点上的掌握程度区间数;
[0073]
试题掌握程度表征模块,用于根据所述知识点掌握程度区间数,获取所述学生对试题的掌握程度区间数;
[0074]
试题得分预测模块,用于根据迭代训练获得的目标模型参数和所述学生对试题的掌握程度区间数,获取试题的预测得分。
[0075]
优选地,所述基于模糊云认知诊断的学生分数预测装置,还包括模型参数获取模块,模型参数获取模块包含参数初始化单元、迭代训练单元;
[0076]
参数初始化单元,用于获取模糊云认知诊断模型的参数先验分布和联合后验分布,并根据所述参数先验分布和所述联合后验分布对模型参数进行初始化;
[0077]
迭代训练单元,用于在模型迭代过程中,从预设参数区间采样获得待定的各模型参数,并计算各模型参数的转移概率;基于所述待定的各模型参数和所述转移概率训练所述模糊云认知诊断模型,并在迭代次数达到预设迭代阈值时,获得目标模型参数。
[0078]
由上可知,采用本发明实施例的基于模糊云认知诊断模型的学生分数预测方法,具有以下有益效果:通过引入云模型理论来改进现有的认知诊断模型,所提出的模糊云认知诊断模型(fuzzy cloud
‑
based cognitive diagnosis framework,fc
‑
cdf)使用由学生认知云转化得到的模糊区间数来刻画学生对于知识点掌握程度的模糊性和不确定性,实现了对学生认知状态的更客观、更全面的表征;此外,fc
‑
cdf通过对学生认知云模型进行求解,来简化模型参数的估算过程,有效缩短了模型执行时间,进而在fc
‑
cdf支持下,有效提升了大规模在线学习场景下学生分数的预测准确度和计算效率。
附图说明
[0079]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0080]
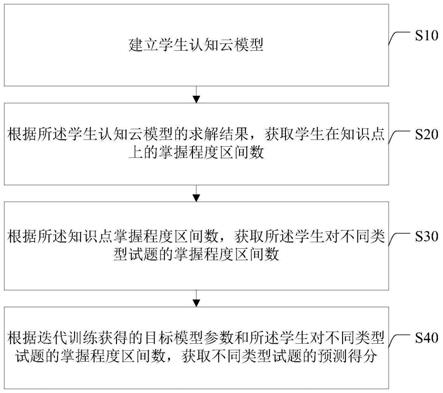
图1为本发明一实施例中基于模糊云认知诊断模型的学生分数预测方法的流程图;
[0081]
图2为本发明一实施例中模糊云认知诊断模型的框架示意图;
[0082]
图3为本发明另一实施例中基于模糊云认知诊断模型的学生分数预测方法的流程图;
[0083]
图4为本发明一实施例中基于模糊云认知诊断的学生分数预测装置的结构示意图;
[0084]
图5为本发明另一实施例中基于模糊云认知诊断的学生分数预测装置的结构示意图。
具体实施方式
[0085]
为使本公开的目的、技术方案和优点更加清楚明白,以下结合具体实施例,并参照附图,对本公开进一步详细说明。
[0086]
如图1所示,本发明一实施例提供的一种基于模糊云认知诊断模型的学生分数预测方法,具体包括以下步骤:
[0087]
步骤s10,建立学生认知云模型。
[0088]
在本实施例中,通过引入云模型理论定义“学生认知云”,并对学生认知云进行数学描述得到学生认知云模型,利用学生认知云模型可以全面客观地刻画学生认知状态的不确定性和波动性。
[0089]
作为优选,步骤s10包括以下步骤:
[0090]
步骤s101,设定学生分值论域和学生认知论域,并根据学生分值论域中的得分对于学生认知论域的隶属度定义学生认知云。
[0091]
具体的,假定学生分值论域x为学生u
i
(i=1,2,
…
,i)在考察了知识点v
k
(k=1,2,
…
,k)的试题集p上的得分,学生认知论域t为学生u
i
(i=1,2,
…
,i)对知识点v
k
(k=1,2,
…
,k)的认知状态,那么学生分值论域x中的得分x对于学生认知论域t的隶属度μ
t
(x),隶属度μ
t
(x)表征了针对得分x,其接近学生对知识点的实际认知状态,称为学生认知云。
[0092]
步骤s102,获取数字特征集,数字特征集中包含认知期望、认知熵和认知超熵。
[0093]
具体的,确定用于刻画学生认知云的三个数字特征,分别为认知期望认知熵和认知超熵并由认知期望认知熵和认知超熵组合得到数字特征集其中,认知期望表征学生对知识点掌握程度的期望值,它对应学生认知论域t中最典型的样本点;认知熵表征学生认知状态的波动范围,它反映了认知期望的不确定性;认知超熵表征学生认知状态的变化频率,它反映了认知熵的不确定性的度量。
[0094]
步骤s103,根据数字特征集建立学生认知云模型。也即,学生认知云模型可以表示为:
[0095]
可理解的,本实施例通过上述步骤建立学生认知云模型,以将学生认知云模型应用到认知诊断模型中,有利于提高认知诊断模型的分数预测准确度和计算效率。
[0096]
步骤s20,根据学生认知云模型的求解结果,获取学生在知识点上的掌握程度区间数。
[0097]
在本实施例中,学生认知云模型c
c
的求解结果为学生认知云模型c
c
中三个数字特征的特征值;学生i在知识点k上的掌握程度区间数包含学生i在知识点k上的掌握程度下限和掌握程度上限且掌握程度下限和掌握程度上限的取值范围均为[0,1],即
[0098]
具体的,首先对学生i在知识点k上的学生认知云模型c
cik
进行求解,获得学生认知云模型c
cik
中三个数字特征的特征值,然后将求解获得的三个特征值输入预设的组合评价模型,获得学生i在知识点k上的掌握程度下限和掌握程度上限进而由学生i在知识点k上的掌握程度下限和掌握程度上限得到学生i在知识点上的掌握程度区间数进一步地,由所有学生的知识点握程度区间可以得到学生在知识点上的掌握程度矩阵其中,i为学生数量,k为知识点数量。
[0099]
作为优选,步骤s20包括以下步骤:
[0100]
步骤s201,获取考察了知识点k的试题集对应的试题数量,并检测试题集对应的试题数量是否大于预设道数。
[0101]
步骤s202,若大于预设道数,则通过逆向认知云算法对学生i在知识点k上的学生认知云模型c
cik
进行求解,获得认知期望认知熵和认知超熵的特征值,并将认知期望认知熵和认知超熵的特征值输入组合评价模型,获得学生i在知识点k上的掌握程度下限和掌握程度上限其中,逆向认知云算法为:
[0102][0103]
公式(5)中,和分别为学生i在知识点k上认知期望、认知熵和认知超熵;r
′
ik
|为得分集合r
′
ik
的集合大小,得分集合r
′
ik
为学生i在考察了知识点k的试题集上的得分集合,可以表示r
′
ik
={r
′
ik1
,r
′
ik2
,
…
},r
′
ikm
为学生i在考察了知识点k的第m道试题上的得分。其中,组合评价模型为:
[0104][0105]
公式(6)中,w为学生认知云的认知超熵的权重,用于调整学生认知云的认知超熵对和的影响深度;max{}为最大值函数;min{}为最小值函数。
[0106]
也即,当考察了知识点k的试题集大于三道题时,获取到学生i在考察了知识点k的试题集上的得分集合r
′
ik
={r
′
ik1
,r
′
ik2
,
…
}之后,将得分集合r
′
ik
中的所有得分数据作为云滴送入逆向云发生器,也即输入到公式(5)所示的逆向认知云算法,得到学生认知云c
cik
的三个数字特征的特征值。进一步的,将上述得到的三个特征值输入公式(6)所示的组合评价模型,得到学生i在知识点k上的掌握程度下限和掌握程度上限
[0107]
步骤s203,根据学生i在知识点k上的掌握程度下限和掌握程度上限获取学生i在知识点k上的掌握程度区间数
[0108]
可理解的,本实施例在对学生的知识点认知状态进行建模的过程中,采用了一个高效、简洁的逆向认知云算法来简化模型参数估算的计算过程,可明显提升认知诊断分析的计算速度,从而能够更好地支持未来的大规模在线学习场景下对于海量历史成绩数据进行快速处理的需求,从而使得在线学习平台为学生提供实时地个性化学习推荐服务成为可能。
[0109]
进一步地,所述步骤s20还包括以下步骤:
[0110]
步骤s204,若小于或等于预设道数,则确定学生认知云模型无效,并通过概率矩阵分解(probabilistic matrix factorization,pmf)方法预测学生得分。
[0111]
也即,当考察了知识点k的试题集小于或等于三道题时,则确定与知识点k相关的数据量不足,无法利用步骤s10构建的学生认知云模型对学生在知识点k上的认知状态进行刻画,需引入pmf方法预测学生得分。
[0112]
pmf的学生得分预测过程为:首先,pmf把学生的得分矩阵x分解成学生和试题的特征矩阵m和h,其中,m∈z
d
×
s
、h∈z
d
×
j
,s为学生数量、j为试题数量,d为潜在特征向量维度。
[0113]
然后,在学生和试题的潜在特征向量分别表示为m
s
和h
j
时,试题得分x满足公式(7)所示的条件分布。
[0114][0115]
公式(7)中,是均值为μ,方差为σ
r
的高斯分布概率密度函数。同时,pmf假设特征矩阵m和h分别满足公式(8)和公式(9)所示的均值为0的高斯分布。
[0116][0117][0118]
公式(8)和(9)中,i为对角阵;σ
m
、σ
h
为方差。
[0119]
进而结合试题得分x满足的条件分布和特征矩阵m和h满足的高斯分布,推导出学生和试题的潜在特征向量的后验分布概率,可以表示为:
[0120][0121]
最后,在对公式(10)两边取对数后,结合梯度下降方法,pmf将预测学生得分的目标函数表示为:
[0122][0123]
公式(11)中,i
sj
为学生s在试题j上是否有答题记录,若有答题记录,则为1,否则为0;λ
m
和λ
h
为正则化系数;|| ||
fro
为frobenius范数。
[0124]
步骤s30,根据知识点掌握程度区间数,获取学生对试题的掌握程度区间数。
[0125]
在本实施例中,试题j包含主观题和客观题;学生i对不同类型试题j的掌握程度区间数包含学生i对不同类型试题j的掌握程度下限和掌握程度上限
[0126]
可理解的,首先判断试题j属于哪种类型,然后将步骤s20获得的知识点掌握程度区间数输入与试题类型匹配的模糊评价模型,得到学生i对试题j的掌握程度下限和掌握程度上限最后由学生i对试题j的掌握程度下限和掌握程度上限得到学生i对试题j的掌握程度区间数进一步地,由所有学生对试题j的掌握程度区间数可以得到学生对试题的掌握程度矩阵其中,i为学生数量,j为试题数量。
[0127]
作为优选,步骤s30包括步骤:
[0128]
步骤s301,检测试题j所属的试题类型。
[0129]
步骤s302,在试题j属于客观题时,获取与客观题匹配的第一模糊评价模型,并根据第一模糊评价模型获取学生i对客观题的掌握程度下限和掌握程度上限其中,第一模糊评价模型为:
[0130][0131]
公式(12)中,和分别为学生i在知识点k(k=1,2,
…
,k)上的掌握程度下限和掌握程度上限;q
jk
为试题j是否考察了知识点k,若q
jk
=1,则试题j考察了知识点k,否则试题j未考察知识点k;∩为模糊交。
[0132]
步骤s303,在试题j属于主观题时,获取与主观题匹配的第二模糊评价模型,并根据第二模糊评价模型获取学生i对主观题的掌握程度下限和掌握程度上限其中,第二模糊评价模型为:
[0133][0134]
公式(13)中,∪为模糊并。
[0135]
步骤s304,根据学生i对主观题和客观题的掌握程度下限和掌握程度上限获取学生i对主观题和客观题的掌握程度区间数
[0136]
步骤s40,根据迭代训练获得的目标模型参数和学生对试题的掌握程度区间数,获取试题的预测得分。
[0137]
在本实施例中,目标模型参数包含试题失误率s
j
和试题猜测率g
j
。优选地,目标模型参数通过步骤s501至步骤s503获得。
[0138]
具体的,针对客观题和主观题,根据试题失误率s
j
和试题猜测率g
j
,结合步骤s30得到的学生i对试题j的掌握程度区间数获得试题j的得分预测区间数进而根据试题j的得分预测区间数得到试题j的预测得分。需要说明的是,针对客观题和主观题,本实施例均采用得分预测模型获取客观题和主观题的得分预测区间数
[0139]
可理解的,本实施例的fc
‑
cdm由学生认知云、学生知识点掌握程度、学生试题掌握程度和试题预测得分四部分组成,如图2所示。
[0140]
作为优选,步骤s40包括以下步骤:
[0141]
步骤s401,对于主观题和客观题,将试题失误率s
j
、试题猜测率g
j
和学生i对试题j的掌握程度区间数输入得分预测模型,以获得试题j的得分预测区间数其中,得分预测模型为:
[0142][0143]
公式(14)中,和分别为学生i在试题j上的预测得分上限和预测得分下限。
[0144]
步骤s402,根据试题j的得分预测区间数计算学生i在试题j上的预测得分f
ij
;其中,预测得分f
ij
的计算公式为:
[0145][0146]
s.t.|r
′
ik
|>n
[0147]
公式(15)中,|r
′
ik
|>n为约束条件;|r
′
ik
|为考察了知识点k的试题集对应的试题数量;n为预设道题。
[0148]
由上可知,采用本发明实施例的基于模糊云认知诊断模型的学生分数预测方法,具有以下有益效果:通过引入云模型理论来改进现有的认知诊断模型,所提出的fc
‑
cdf使用由学生认知云转化得到的模糊区间数来刻画学生对于知识点掌握程度的模糊性和不确定性,实现了对学生认知状态的更客观、更全面的表征;此外,fc
‑
cdf通过对学生认知云模
型进行求解,来简化模型参数的估算过程,有效缩短了模型执行时间,进而在fc
‑
cdf支持下,有效提升了大规模在线学习场景下学生分数的预测准确度和计算效率。
[0149]
在一可选实施例中,如图3所示,所述基于模糊云认知诊断模型的学生分数预测方法还包括以下步骤:
[0150]
步骤s501,获取模糊云认知诊断模型的参数先验分布和联合后验分布,并根据参数先验分布和联合后验分布对模型参数进行初始化。
[0151]
在本实施例中,fc
‑
cdm的模型参数包含试题失误率s
j
和试题猜测率g
j
,相应地,参数先验分布分别为:
[0152]
s
j
~beta(m
s
,n
s
,min
s
,max
s
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(16)
[0153]
g
j
~beta(m
g
,n
g
,min
g
,max
g
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(17)
[0154]
公式(16)和公式(17)中,beta(m,n,min,max)是一个定义在[min,max]区间的四参数贝塔分布,m和n是先验分布的两个形状参数。
[0155]
在给定得分矩阵r的情况下,s
j
和g
j
的联合后验分布p(s,g|r)为:
[0156]
p(s,g|r)
∝
l(s,g)p(s)p(g)
ꢀꢀꢀꢀꢀꢀꢀ
(18)
[0157]
公式(18)中,p(s)和p(g)分别为s
j
和g
j
对应分布的概率密度;l(s,g)为fc
‑
cdm的联合似然函数。
[0158]
进一步地,根据公式(16)和公式(17)所示的模型参数s
j
和g
j
的先验分布,以及公式(18)所示的联合后验分布p(s,g|r)对模型参数s
j
和g
j
进行初始化设置。
[0159]
步骤s502,在模型迭代过程中,从预设参数区间采样获得待定的各模型参数,并计算各模型参数的转移概率;其中,每一个模型参数均对应一个预设参数区间。
[0160]
在模型参数包含s
j
和g
j
时,从预设参数区间随机采样获得的待定的模型参数分别为s
w
和g
w
,可以表示为:
[0161]
s
w
~u(s
w
‑1‑
ε
s
,s
w
‑1+ε
s
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(19)
[0162]
g
w
~u(g
w
‑1‑
ε
g
,g
w
‑1+ε
g
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(20)
[0163]
公式(19)和公式(20)中,u(u
‑
ε
u
,u+ε
u
)为预设参数区间;ε为各模型参数u={s
j
,g
j
}的调整因子。可选地,ε=0.1。
[0164]
且模型参数的转移概率的计算公式为:
[0165][0166]
步骤s503,基于待定的各模型参数和转移概率训练模糊云认知诊断模型,并在迭代次数达到预设迭代阈值时,获得目标模型参数。可选地,为了便于计算转移概率,设定p(s)和p(g)分别为s
j
和g
j
对应分布的概率密度。
[0167]
也即,按照步骤s502的方法对fc
‑
cdm进行迭代训练,直至迭代次数达到预设迭代阈值,得到目标模型参数。可理解的,本实施例通过上述步骤实现模型参数的估算。
[0168]
以下结合基于模糊云认知诊断模型的学生分数预测方法的实验对比分析情况,对本公开进一步详细说明。
[0169]
1)设置fc
‑
cdm的相关参数,fc
‑
cdm的相关参数包含参数先验分布、权重、迭代次数等。
[0170]
fc
‑
cdm中涉及到的参数先验分布设置为:s
j
~beta(m
s
=1,n
s
=2,min
s
=0,max
s
=0.6);g
j
~beta(m
g
=1,n
g
=2,min
g
=0,max
g
=0.6)。
[0171]
fc
‑
cdm中涉及到的认知超熵的权重w设置为0.1。
[0172]
fc
‑
cdm训练算法的迭代次数设置为w=5000,并取后2500次迭代训练输出的每个模型参数的估值来计算每个模型参数的平均值,将平均值作为最终的目标模型参数。
[0173]
2)设置模型评估指标:采用根均方误差(rmse)和平均绝对误差(mae)作为模型评估指标;其中rmse和mae分别表示为:
[0174][0175][0176]
公式(22)和公式(23)中,n为测试的学生总人数;f
i
为学生i的预测得分;r
i
为学生i的实际得分。
[0177]
3)设置对比模型,对比模型选择了二个经典模型和二个最新的改进模型,经典模型分别是pmf和采用em算法的dina模型(后续称为em
‑
dina),最新的改进模型分别是fuzzycdf模型和neuralcdm模型。
[0178]
4)构建训练集和测试集:以frcsub、math1、math2和构建的仿真数据集(后续称为simulation)为实验数据集,并采用五折交叉验证法,随机选取每个学生的80%得分数据作为训练集,剩余的20%作为测试集进行测试。其中,frcsub是中学生提交的分数和减法知识点的客观题测试数据集,涉及536名学生、8个知识点、20道题;math1和math2是两次高中生期末数学考试的客观题与主观题答题数据,math1涉及4209名学生、11个知识点、15道客观题和5道主观题,而math2涉及3911名学生、16个知识点、16道客观题和4道主观题;simulation包含1000名学生,100道试题,10个知识点,并设定每个知识点被考察的次数不低于8次。
[0179]
5)评估模型在不同实验数据集上的预测效果,实验结果如表1所示。
[0180]
表1 各模型性能比较
[0181][0182]
由表1可知,在学生对于每个知识点的得分数据充足时,例如frcsub和simulation,fc
‑
cdm性能明显优于其他模型,能够更全面、准确的刻画学生的认知状态,并
准确的预测其在未知试题上的得分情况。而在知识点得分数据稀疏的情况下,例如math1和math2上,由于试题数量的限制,使得fc
‑
cdm中的学生认知云受到数据缺失问题的干扰,最终导致其预测效果与pmf的结果接近。
[0183]
以rmse值为例,fc
‑
cdm在math1和math2上的rmse值稍高于最优的fuzzycdf,分别为0.59%和1.19%。但由于fuzzycdf的计算负担较重,在模型训练过程中中训练所需时间是fc
‑
cdm的近百倍,因此在实际应用中,在学生规模和试题规模均较大的场景下(例如simulation),fc
‑
cdm的预测效果优于fuzzycdf。
[0184]
6)评估模型训练过程的执行时间,实验结果如表2所示。实验时采用相同的处理器(即cpu)和存储器进行训练;此外,为提升neuralcdm的训练效率,额外为其引入一个gpu进行加速。
[0185]
表2 各模型训练过程的执行时间(秒)
[0186][0187]
从表2可知,fc
‑
cdf在训练过程的执行时间明显优于fuzzycdf和neuralcdm。fuzzycdf由于计算负担较重,在math1和math2上的执行时间分别是fc
‑
cdf的72.2倍和95.3倍,在另外两个数据集上的执行性能也远逊于fc
‑
cdf。对于neuralcdm,尽管利用额外的gpu对其进行了加速,但其执行性能也远逊于fc
‑
cdf,以math1为例,neuralcdm的执行时间是fc
‑
cdf的25.8倍。
[0188]
此外,尽管math2的学生规模小于math1,但由于em
‑
dina执行时间随着知识点的增加,呈指数级的增加,使得em
‑
dina在math2上的执行时间急剧增加。例如,在考察的知识点数目较少的数据集中(frcsub中包含8个知识点,math1包含11个知识点,simulation包含5个知识点),em
‑
dina具有优秀的执行时间,但在知识点数目继续增加时,em
‑
dina执行时间会急剧增加,例如,math2考察了16个知识点,math1只考察了11个识点,em
‑
dina在math2上的执行时间是math1的29.98倍。而fc
‑
cdf的执行时间主要受学生规模和试题的影响,这使得fc
‑
cdf在math2上的执行时间优于在math1上的执行时间。
[0189]
因此,可以预见对于大规模在线学习场景,当知识点数目增加到一定程度时,fc
‑
cdf的整体性能会明显优于em
‑
dina,从而具有更好的实用效果和应用可行性。
[0190]
如图4所示,此外,本发明一实施例还提供了一种基于模糊云认知诊断的学生分数预测装置,包括认知云建模模块110、知识点掌握程度表征模块120、试题掌握程度表征模块130和试题得分预测模块140,各功能模块的详细说明如下:
[0191]
认知云建模模块110,用于建立学生认知云模型;
[0192]
知识点掌握程度表征模块120,用于根据学生认知云模型的求解结果,获取学生在
知识点上的掌握程度区间数;
[0193]
试题掌握程度表征模块130,用于根据知识点掌握程度区间数,获取学生对试题的掌握程度区间数;
[0194]
试题得分预测模块140,用于根据迭代训练获得的目标模型参数和学生对试题的掌握程度区间数,获取试题的预测得分。
[0195]
上述实施例的装置用于实现前述实施例中相应的方法,并且具有相应的方法实施例的有益效果,在此不再赘述。
[0196]
进一步地,所述认知云建模模块110包括以下单元,各功能单元的详细说明如下:
[0197]
认知云定义单元,用于设定学生分值论域和学生认知论域,并根据学生分值论域中的得分对于学生认知论域的隶属度定义学生认知云;
[0198]
特征获取单元,用于获取数字特征集,数字特征集中包含认知期望、认知熵和认知超熵;
[0199]
建模单元,用于根据数字特征集建立学生认知云模型。
[0200]
进一步地,所述知识点掌握程度表征模块120包括以下单元,各功能单元的详细说明如下:
[0201]
试题集检测单元,用于获取考察了知识点k的试题集对应的试题数量,并检测试题集对应的试题数量是否大于预设道数;
[0202]
逆向求解单元,用于若大于预设道数,则通过逆向认知云算法对学生i在知识点k上的学生认知云模型c
cik
进行求解,获得认知期望认知熵和认知超熵的特征值,并将所有特征值输入组合评价模型,获得学生i在知识点k上的掌握程度下限和掌握程度上限
[0203]
第一区间获取单元,用于根据学生i在知识点k上的掌握程度下限和掌握程度上限获取学生i在知识点k上的掌握程度区间数
[0204]
进一步地,所述知识点掌握程度表征模块120还包括以下单元,各功能单元的详细说明如下:
[0205]
学生分数预测单元,用于若小于预设道数,则确定学生认知云模型无效,并通过概率矩阵分解方法预测学生得分。
[0206]
进一步地,所述试题掌握程度表征模块130包括以下单元,各功能单元的详细说明如下:
[0207]
试题类型检测单元,用于检测试题j所属的试题类型;
[0208]
客观题评价单元,用于在试题j属于客观题时,获取与客观题匹配的第一模糊评价模型,并根据第一模糊评价模型获取学生i对客观题的掌握程度下限和掌握程度上限
[0209]
主观题评价单元,用于在试题j属于主观题时,获取与主观题匹配的第二模糊评价模型,并根据第二模糊评价模型获取学生i对主观题的掌握程度下限和掌握程度上限
[0210]
第二区间获取单元,用于根据学生i对主观题和客观题的掌握程度下限和掌握程度上限获取学生i对主观题和客观题的掌握程度区间数
[0211]
进一步地,在目标模型参数包含试题失误率和试题猜测率时,所述试题得分预测模块140包括以下单元,各功能单元的详细说明如下:
[0212]
得分区间获取单元,用于对于主观题和客观题,将试题失误率s
j
、试题猜测率g
j
和学生i对试题j的掌握程度区间数输入得分预测模型,以获得试题j的得分预测区间数
[0213]
得分预测单元,用于根据得分预测区间数计算学生i在试题j上的预测得分f
ij
。
[0214]
进一步地,如图5所示,所述基于模糊云认知诊断的学生分数预测装置,还包括模型参数获取模块150,模型参数获取模块150包含参数初始化单元、迭代训练单元,各功能单元的详细说明如下:
[0215]
参数初始化单元,用于获取模糊云认知诊断模型的参数先验分布和联合后验分布,并根据参数先验分布和联合后验分布对模型参数进行初始化;
[0216]
迭代训练单元,用于在模型迭代过程中,从预设参数区间采样获得待定的各模型参数,并计算各模型参数的转移概率;以及基于待定的各模型参数和转移概率训练模糊云认知诊断模型,并在迭代次数达到预设迭代阈值时,获得目标模型参数。
[0217]
所属领域的普通技术人员应当理解:以上任何实施例的讨论仅为示例性的,并非旨在暗示本公开的范围(包括权利要求)被限于这些例子;在本公开的思路下,以上实施例或者不同实施例中的技术特征之间也可以进行组合,步骤可以以任意顺序实现,并存在如述的本发明实施例的,不同方面的许多其它变化,为了简明它们没有在细节中提供。
[0218]
本发明实施例旨在涵盖落入所附权利要求的宽泛范围之内的所有这样的替换、修改和变型。因此,凡在本发明实施例的精神和原则之内,所做的任何省略、修改、等同替换、改进等,均应包含在本公开的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1